💡
27.3.2024 modified to use Workload Federation Identity instead of a separate Azure Service Principal
In the previous article, I focused on making an automated backup of the Intune configuration.
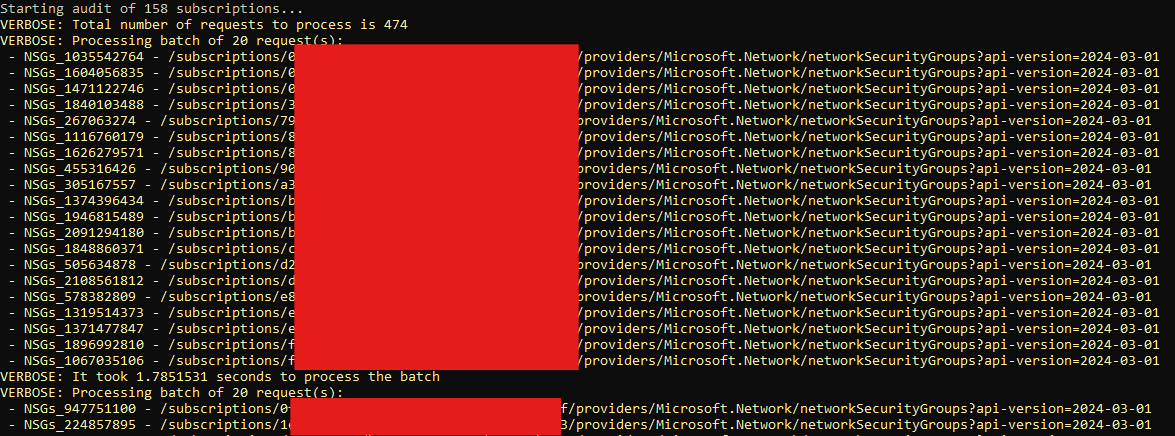
Today I will show you, how to regularly back up your Azure environment configuration using the great EntraExporter PowerShell module and Azure DevOps Pipeline. What makes this so special is that also the authors of the changes are included in the backup.
The result?
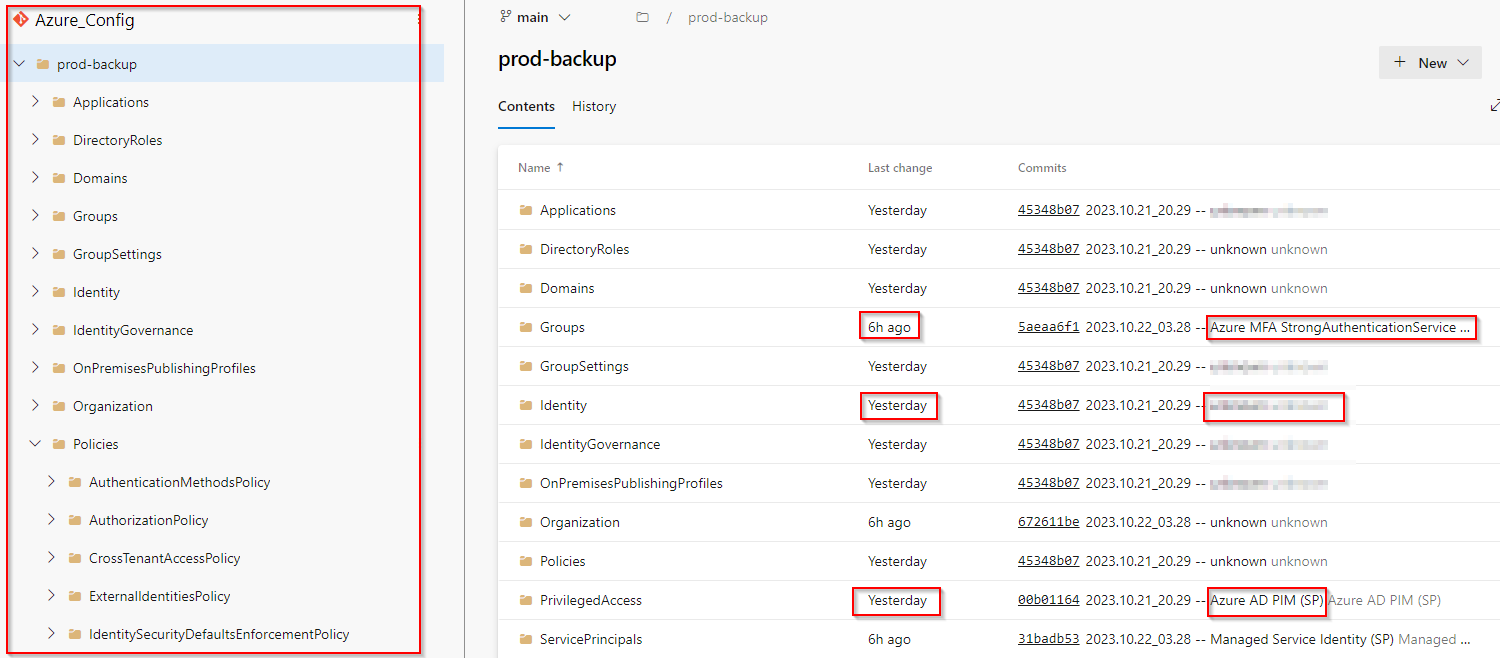
You can easily browse through your Azure environment history saved in your GIT repository and see who made what change and when it happened 🤯
💡
Saving change author is quite useful, because by default Azure Audit log stores audit events for up to 30 days only!
Main benefits of this solution
It is free of charge *
All your Azure configuration will be regularly backed up to your private Azure DevOps GIT repository
Visibility to Azure changes made during the time including the author of such change
Runs in Azure DevOps Pipeline a.k.a. purely code-driven & cloud-driven (no on-premises requirements whatsoever)
* Free DevOps pipeline run is limited to 1800 minutes per month. One full Azure backup run takes approximately 25 minutes (but that depends on the size of your environment) and is run every day, so do the math. But you can always take the pipeline code and run it as a scheduled task on your server without any limitations 😎
Requirements
Let's do this
This solution needs:
Azure DevOps repository
Create a private Azure DevOps repository
Go to https://dev.azure.com/ and create a PRIVATE new repository (project).
Azure_Config in my case.
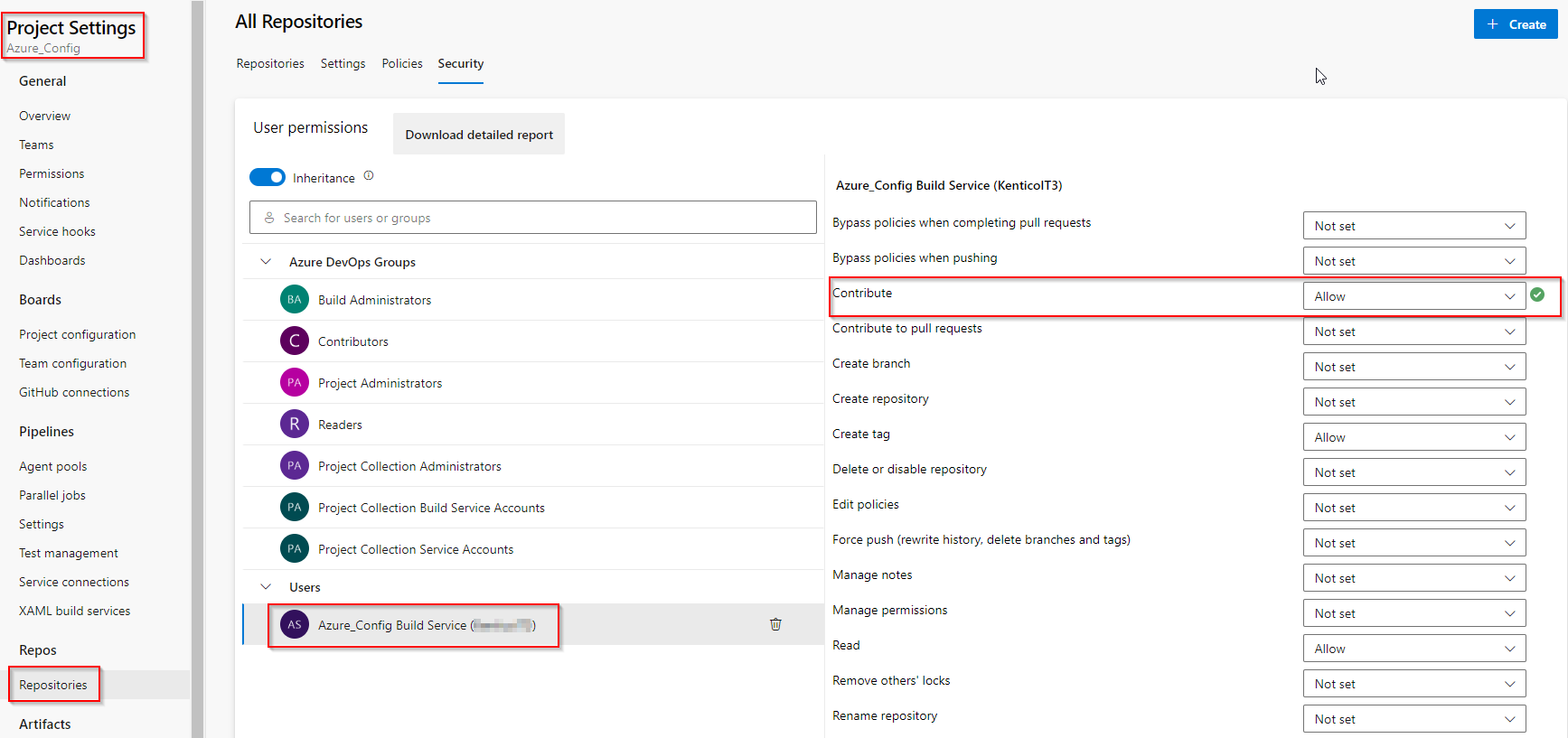
Assign contribute permission
Go to Project settings > Repositories > Security and grant Contribute 'ALLOW' permission to Build Service account. Otherwise, pipeline jobs will fail when a commit is made.
Workload Federating identity
Create Workload Federating identity
Instead of using Azure Service Principal (SP) to authenticate to Graph Api, we will use Workload Federating identity. The main benefit is that you don't have to worry about passing SP secret to your pipeline, renewing it, etc.
How to create a Workload Federating identity is outside of the scope of this article and is described in my other post.
It is just a few steps; the only important thing is to remember what name you used to create Service connection name during the setup, because we will use it in our pipeline later.
In my case, it is azure_backup_connection.
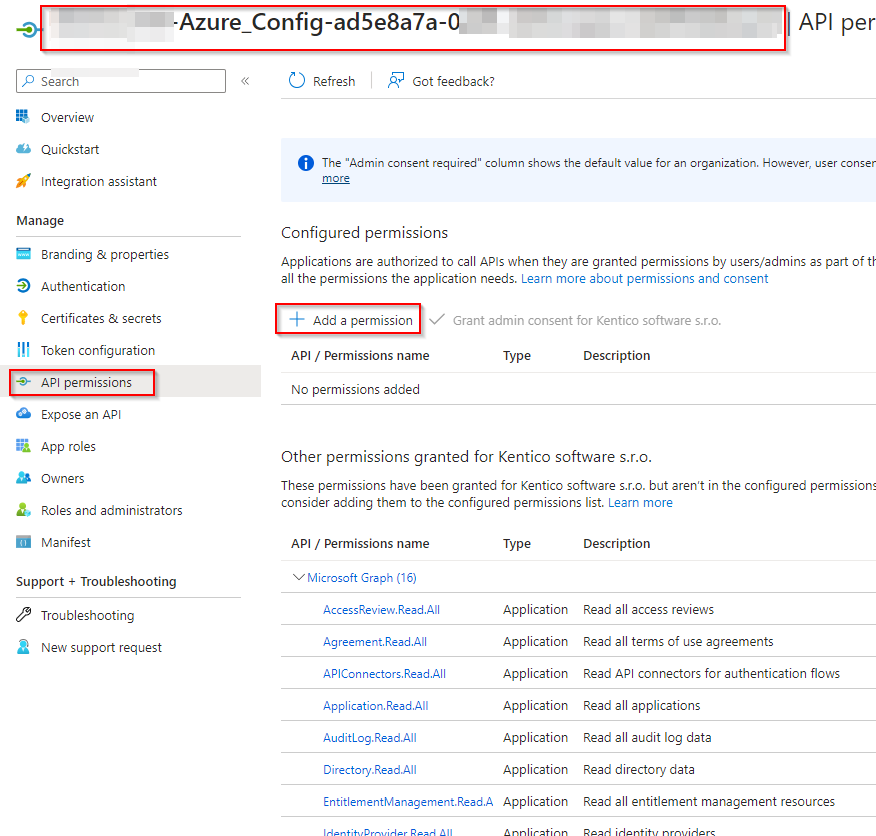
Grant required permissions
Grant the following Graph API application permissions to the created Workload Federating Identity:
💡
To grant permissions programmatically, you can use
Grant-AzureServicePrincipalPermission (part of the
AzureApplicationStuff module)
💡
Don't forget to Grant admin consent for all those permissions too!
Grant required Directory roles
If PIMResources (or All) export is selected, you need to grant RBAC role Management Group Reader at the Tenant Root Group level (to be able to read Management Groups) to the created Workload Federating Identity
If IAM (or All) export is selected, you need to grant RBAC role Reader at the Tenant Root Group level (to be able to read all subscriptions and their resources) to the created Workload Federating Identity
Azure DevOps repository pipeline
The pipeline is where all the magic happens. It is in fact script that defines what should happen.
Create new Pipeline
- Now go to
Pipelines and create the pipeline using Create Pipeline button

By default this pipeline will be started every day at 2 am. If you want to change that, just alter the cron key value (cron: '0 2 * * *'). You can use https://crontab.guru to generate a new one.
Customize predefined pipeline variables
At the beginning of the pipeline code, there are some variables defined that need to be set to match your environment.

SERVICE_CONNECTION_NAME
- name of the workload identity service connection (
Service connection name) created earlier
USER_EMAIL
you can leave it as it is
default email that will be used as commits author email, something like Azure_Backupper@contoso.com (or whatever you wish)
USER_NAME
you can leave it as it is
default username that will be used as commits author, something like Azure_Backupper (or whatever you wish)
Save & Run the pipeline
Now when the pipeline is ready, save it by choosing Save and run . This way you will immediately see whether the pipeline is working fine 👍

Beware that first run will take a lot longer then subsequent runs! The reason is huge amount of files that needs to be backed up. Following runs only captures changes since the last backup.
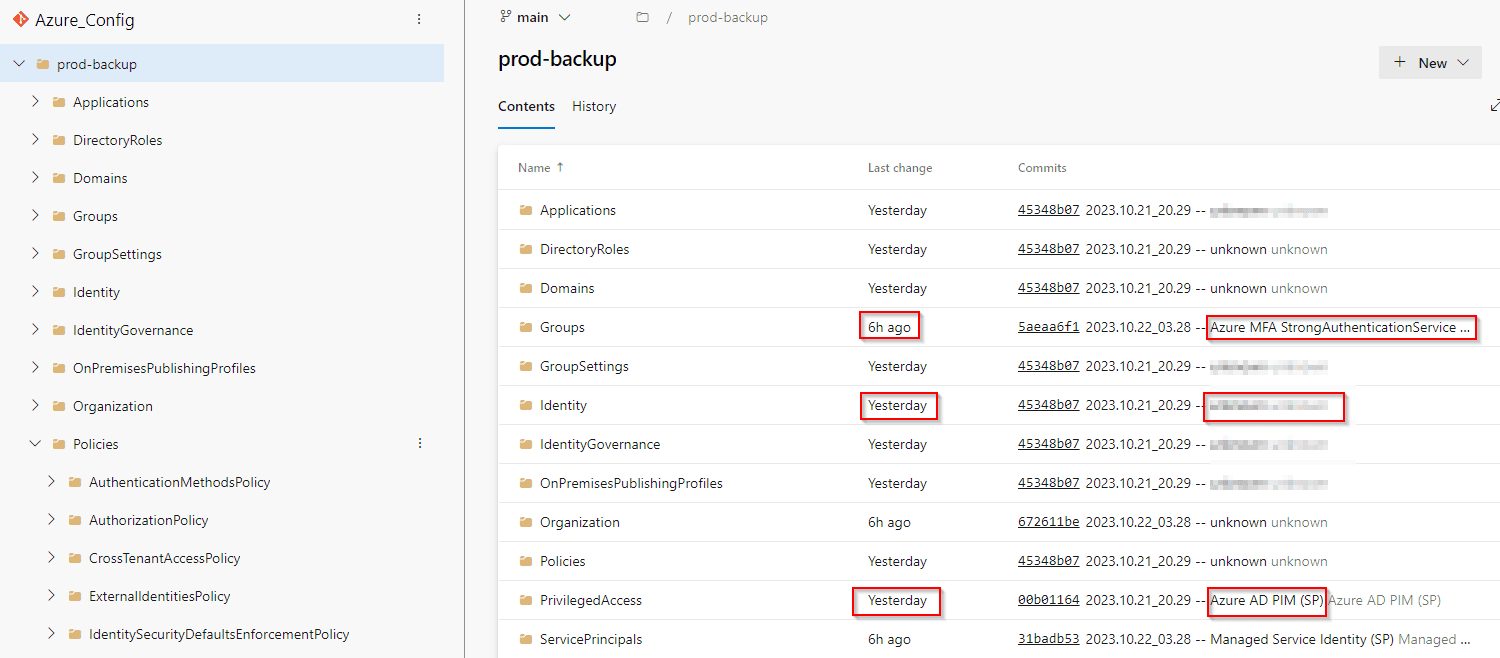
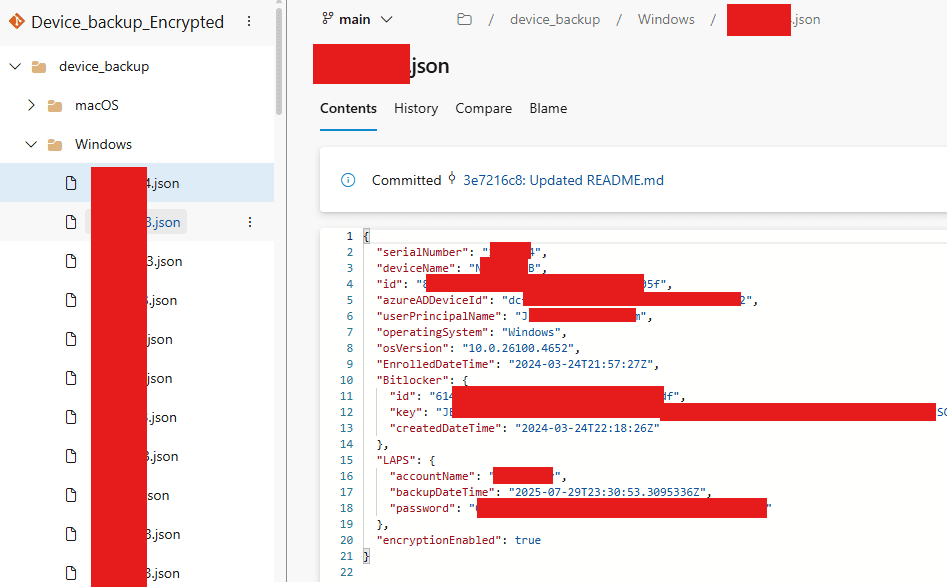
After the pipeline finishes, you should see that prod-backup folder was created and filled with your Azure configuration JSON files, including who made them 😍
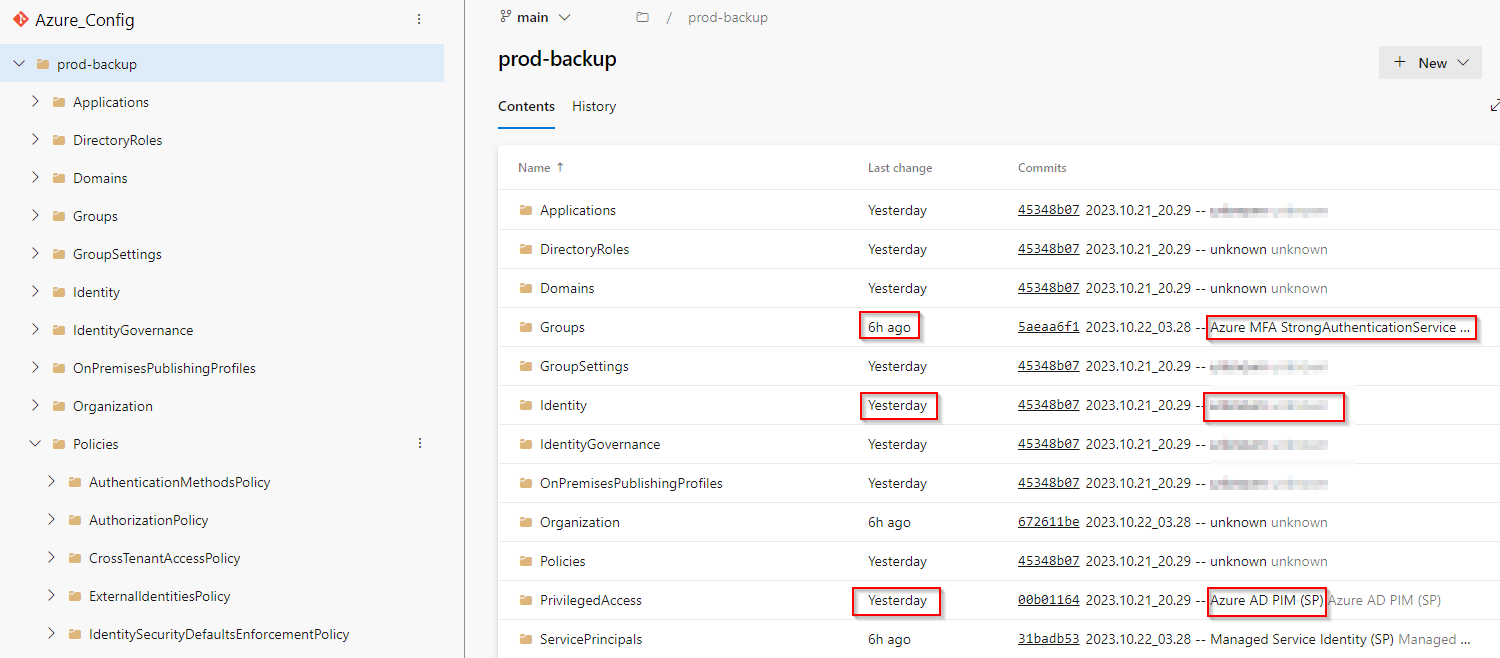
According to the schedule, it will be automatically started by default every day at 2 a.m.
What does this pipeline do?
Install EntraExporter module
Export Azure configuration backup to prod-backup folder
If a change in configuration is detected
For each changed file find who did it
- by searching the Azure Audit log for particular ResourceId changes since the last config commit date
Group changed files by the author(s) who changed them
Commit each group separately by using the author name(s)
Create Git TAG
- name of all changes authors will be included in the TAG description
If there is no change
How to
Send a notification in case the pipeline fails
It is useful to be notified when the pipeline fails. For example because application secret expired etc. To do so go to Project settings > Notifications > New Subscription and select Build > A Build fails end finish the wizard.

Get changes made between specified dates
To get a visual list of changes made in your Azure configuration between specified dates, go to Repos > Tags select the first Tag and Set as compare tag, then select the second one and run the comparison by Compare tags
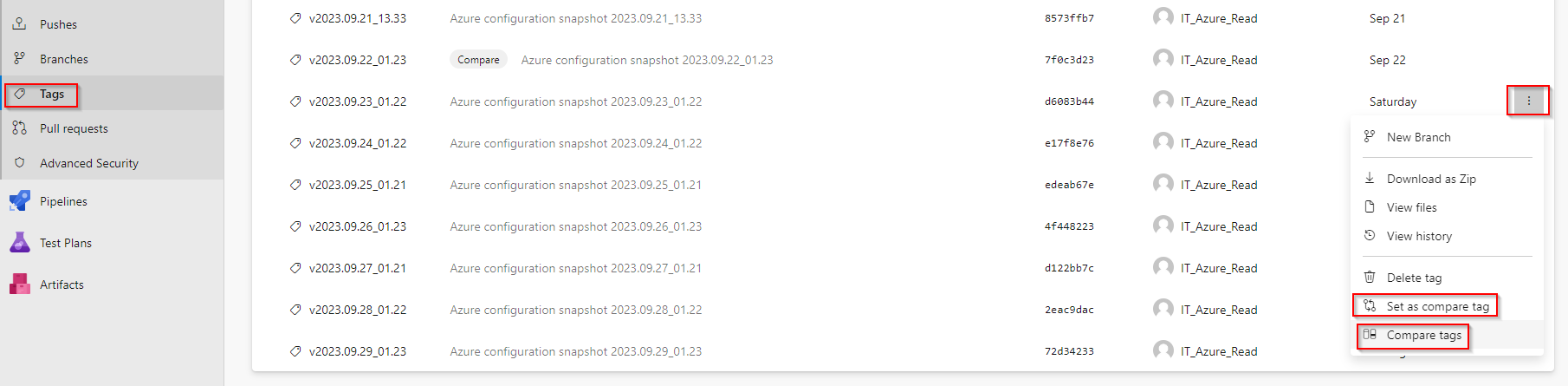
On the result page select Files and enjoy the view 🙂
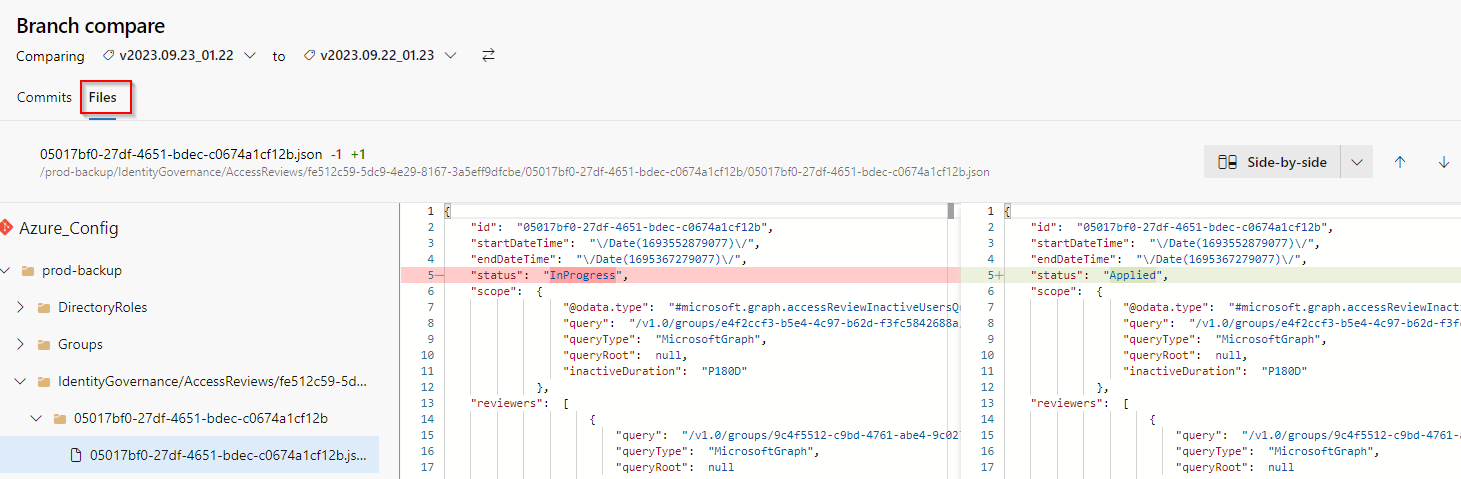
Strikethrough files are settings that were deleted, plus sign on the right side of the file means it is a new setting that was created.
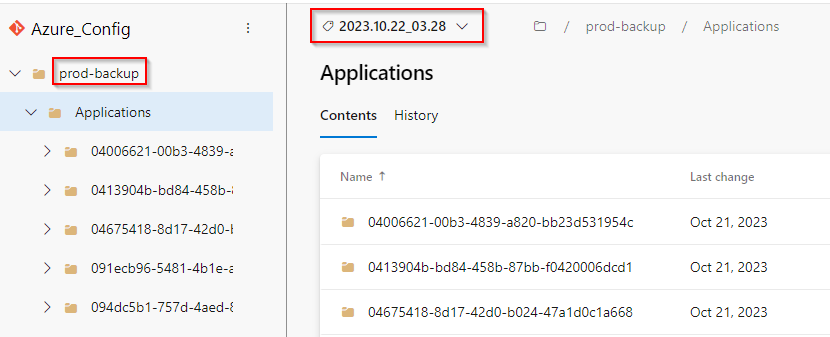
Show the Azure configuration status on a specific date
To see what your Azure environment looked like on a specific date in the past. Go to Repos > Tags > Pick the nearest older Tag > Open the folder prod-backup and browse the content (exported JSON configuration files).
This way you will see what your Azure looked like just before the specified date.
To see what changes were made during this time, compare this Tag with the nearest newer Tag.
Beware that if someone made some changes in the configuration and reverted them back before the next backup occurred, they won't be captured (obviously).
Change what should be included in the backup
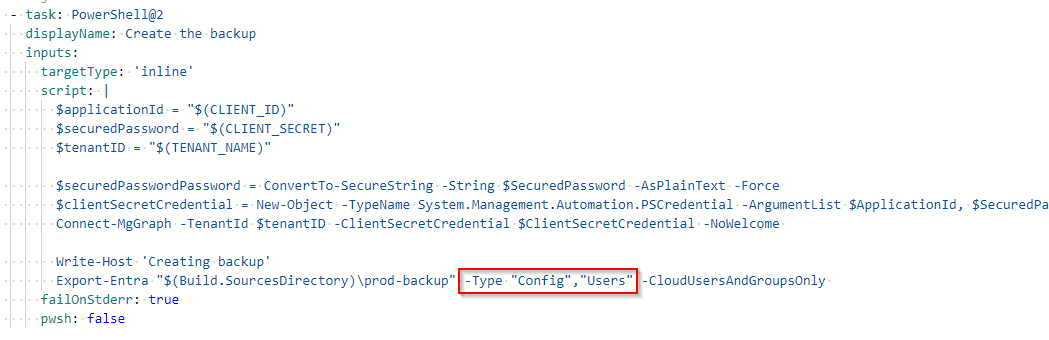
To modify what should be backed up, you must edit Create the backup task section in the Pipeline configuration code.
Go to Pipelines > <yourPipeline> > click Edit > find the line where Export-Entra command is being called and modify its parameters by replacing the -All parameter with -Type and some arguments. What arguments can be used can be found in the official documentation.
So the result can look like this 👇
Restore the backup
Unfortunately, there is no built-in way for backup restore in the EntraExporter tool. Hence in case you need to restore some configuration, you have to do it manually.
How the change author(s) are managed
In the GIT repository, if you want to see who changed file XYZ, you check who was the author of the commit that changed such file. Therefore it was only logical to use the same approach to "save" information about who has changed the Azure configuration (JSON file).
How the change author is found?
When change is detected in the created backup (some JSON configuration file is changed) the pipeline will
Get a list of all changed files
Getting the last configuration backup commit date ($lastCommitDate)
- if no backup commit exists, just the last 24 hours old events of the Azure Audit log will be searched (this limitation is because the first backup can have thousands of files, and thousands of events can be in the Audit log which by my testing leads to exceeding 60 minutes pipeline limit)
For each changed file find out who changed it by
- searching its ID in the Azure Audit log (between dates saved in
$lastCommitDate and start time of this backup run) and making note of all authors that made some changes there
Group the changed files by found authors and make a commit for each group where the list of all authors that changed such files is used in the commit name and as the commit author
Put all found authors into the Git Tag description too
Good to know
The list of author(s) doesn't have to be 100% accurate. If you need 100% accuracy (because of security incident etc), use a command Get-MgAuditLogDirectoryAudit
- for example when someone makes a change in the Azure right after the backup starts. Such change can be captured, but the author will not, because the Azure log is searched from the last commit date to the start of the backup task only. If the search ended at the backup finish instead, it could lead to an opposite situation when author list could contain someone who didn't make the change that was captured in the backup.
The list of commit authors shows who has made any changes to committed files (since the last commit). It doesn't show who made what particular change
If a change was made by an application (instead of a user), the name of the application is used as the author name with (SP) a suffix (for example User Management (SP))
If the author of the changed configuration wasn't found in the Audit log, unknown is used instead
Because the free pipeline has limited run time, before searching for the change author I make a calculation (function _enoughTime) whether there is enough time left for committing changes, etc, and if it is not, I skip searching for the author. It is more important to have config backup than risking the whole pipeline to fail
- Therefore it is very important to modify the pipeline variable
PIPELINE_TIME_LIMIT in case, 60 minutes limit is not applied in your case
Summary
If you finished all the required steps, you now have a working backup solution for your Azure configuration which you can easily use for tracking changes & blaming the change authors 😎
Links